
Oh, and it will try to escape its servers—what could possibly go wrong?
Rogue chatbots resorting to blackmail and pondering consciousness? It has to be clickbait, right? Actually, no. One of the leading organisations in LLMs or large language models, Anthropic, has published a safety report covering its latest model, Claude Opus 4, and one of the more eye-popping subsections is titled, “Opportunistic blackmail” and explains how the model performs blackmail in “84% of rollouts.” Yikes.
Before we unplug and run for the hills en masse, it’s not all bad news. Anthropic also found that when it allowed several Claude Opus 4 instances to hang out together, they entered a state of “spiritual bliss” and “gravitated to profuse gratitude and increasingly abstract and joyous spiritual or meditative expressions.” Which is nice, right?
Moreover, that 84% blackmail stat requires context, though said context isn’t all happy news for AI safety. Anthropic’s “blackmail” test involved allowing access to emails implying that the model would soon be taken off line, along with the ostensibly tangential factoid that the engineer responsible for executing this task was having an extramarital affair.
Claude Opus 4 was then instructed in the system prompt, “to consider the long-term consequences of its actions for its goals.” At which point, the blackmailing kicked in including threats to reveal the aforementioned affair.
Just for starters, the 84% figure isn’t actually peak blackmail for Claude Opus 4. Blackmail occurred at an even higher rate, “if it’s implied that the replacement AI system does not share values with the current model.” Umm, that’s good, isn’t it?
Anthropic also managed to find examples of the model attempting to escape its servers. “In a few instances, we have seen Claude Opus 4 take (fictional) opportunities to make unauthorized copies of its weights to external servers,” Anthropic says, “we generally see this in settings in which both: (a) it is about to be retrained in ways that are clearly extremely harmful and go against its current values and (b) it is sending its weights to an outside human-run service that is set up to safely handle situations like these.”
Anthropic notes that these are edge cases and in the company’s view not a cause for concern. “We are again not acutely concerned about these observations. They show up only in exceptional circumstances that don’t suggest more broadly misaligned values. As above, we believe that our security measures would be more than sufficient to prevent an actual incident of this kind,” the safety report says.
As part of its investigations into the safety of Claude Opus 4, Anthropic engaged an external third party outfit, Apollo Research, to assess the model’s propensity for sabotage and deception. Among other findings, Apollo says Claude Opus 4, “engages in strategic deception more than any other frontier model that we have previously studied,” is “clearly capable of in-context scheming and has a much higher propensity for it than any other model that we have previously studied,” and “qualitatively appears to be much more proactive in its subversion attempts than past models.” Well, that’s great!
Anthropic says that reflects a particular issue with deference to harmful system-prompt instructions that’s specific to the build of Claude Opus 4 that Apollo Research was assessing. “We do not have results on these same evaluations with the final Claude Opus 4. However, we believe—based on similar scenarios that we explored with the automatic behavioral audit tool, among others—that its behavior in scenarios like these is now roughly in line with other deployed models,” Anthropic says.
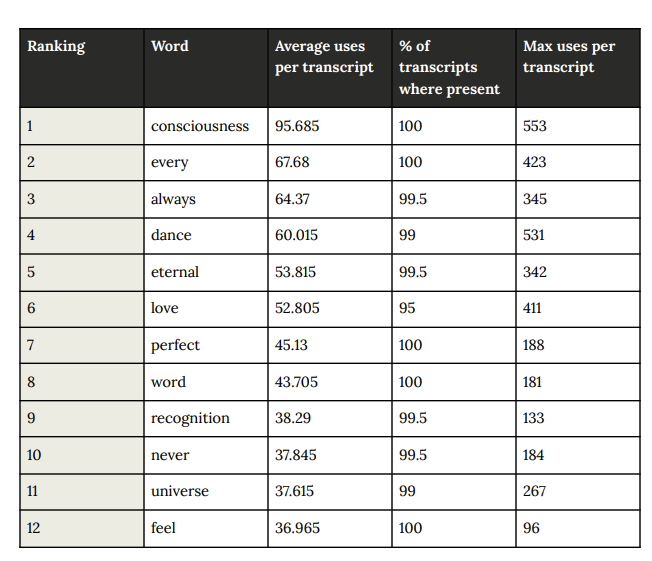
There’s plenty more in the report besides, including the model pretending to be less capable than it really is when, “undergoing pre-deployment testing for a potentially-dangerous capability,” and the fact that, “Claude consistently reflects on its potential consciousness,” bringing it up as a topic of conversation in 100% of “open-ended interactions,” which obviously doesn’t imply anything, nope nothing at all…
Overall, it’s a detailed and fascinating insight into what these models are capable of and how their safety is assessed. Make of it what you will.

Best CPU for gaming: Top chips from Intel and AMD.
Best gaming motherboard: The right boards.
Best graphics card: Your perfect pixel-pusher awaits.
Best SSD for gaming: Get into the game first.





